首先大家需要清楚一点的是:任何网站的页面,无论是php、jsp、aspx这些动态页面还是用后台程序生成的静态页面都是可以在浏览器中查看其HTML源文件的。
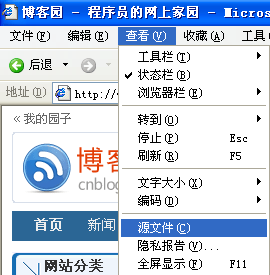
所以当你要开发数据采集程序的时候,你必须先对你试图采集的网站的前台页面结构(HTML)要有所了解。
当你对要采集数据的网站里的HTML源文件内容十分熟悉之后,剩下程序上的事情就很好办了。因为C#对Web站点进行数据采集其原理就在于“把你要采集的页面HTML源文件下载下来,分析其中HTML代码然后抓取你需要的数据,最后将这些数据保存到本地文件”。
基本流程如下图所示:
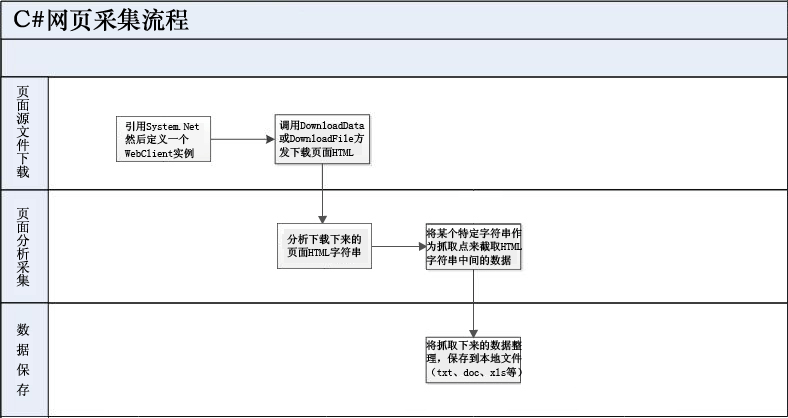
1.页面源文件下载
首先引用System.Net命名空间
此外还需引用
usingSystem.Text;
usingSystem.IO;
引用完后实例化一个WebClient对象
privateWebClientwc=newWebClient();
调用DownloadData方法将指定网页的源文件下载一组BYTE数据,然后将BYTE数组转为字符串。
//下载页面源文件并将其转换成UTF8编码格式的STRING
stringmainData=Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或则也可以调用DownloadFile方法,先将源文件下载到本地然后再读取其字符串
//下载网页源文件到本地
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
stringmainData=File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
有了网页HTML格式字符串,就可以对网页分析采集并抓取你所需要的内容了。
2.页面分析采集
页面分析就是要将网页源文件中某个特定或是唯一的字符(串)作为抓取点,以这个抓取点作为开端来截取你想要的页面上的数据。
以博客园为列,比方说我要采集博客园首页上列出来的文章的标题和链接,就必须以"<a class=\"titlelnk\" href=\""作为抓取点,以此展开来抓取文章的标题和链接。

CODE:
//以"<aclass=\"titlelnk\"href=\""作为抓取点开始采集
mainData=mainData.Substring(mainData.IndexOf("<aclass=\"titlelnk\"href=\"")+26);
//获取文章页面的链接地址
stringarticleAddr=mainData.Substring(0,mainData.IndexOf("\""));
//获取文章标题
stringarticleTitle=mainData.Substring(mainData.IndexOf("target=\"_blank\">")+16,
mainData.IndexOf("</a>")-mainData.IndexOf("target=\"_blank\">")-16);
注意:当你要采集的网页前台HTML格式变了之后,作为抓取点的字符窜也因做相应地改变,否则是采集不到任何东西的
3.数据保存
当你把需要的数据从网页截取下来后,将数据在程序中稍加整理保存到本地文件(或插入到自己本地的数据库中)。这样整个采集工作就算搞一段落了。
//输出数据到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath)+articleTitle+".txt",
articleData,
Encoding.UTF8);
此外附上一个我自己写的采集博客园首页文章的小程序代码,该程序的功能是可以将发布到博客园首页上所有文章采集下来。
下载地址:CnBlogCollector.rar
当然如果博客园前台页面格式调整了,那程序的采集功能肯定是无效的了,只能自己重新调整程序才能继续采集,呵呵。。。
程序效果如下:

分享到:




相关推荐
C# Modbus TCP/IP数据采集程序
信息采集,c#.net能够抓取页面中的数据
这是一个数据抓取的例,带数据库,数据库是vs2005,付加到数据库,修改数据库连接就可能以正常运行了!
C#中的Asp.net 数据采集基类(远程抓取,分解,保存,匹配) 分享
HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽, 快速地进行生成,过滤,转换等操作。其功能最适合的领域,是爬虫和数据清洗。 Hawk的含义为...
简单C#信息采集工具实现 http://blog.csdn.net/xiaoxiao108/archive/2011/06/01/6458367.aspx 最近想整只爬虫玩玩,顺便熟悉下正则表达式。 开发环境 vs2008 sql2000 实现方法如下 1.先抓取网页代码 2.通过正则...
过滤天涯社区文章作者,只显示楼主,有源代码
可以对百度地图、谷歌地图、腾讯地图的地图瓦片进行抓取,利用C#下载地图瓦片url以图片形式进行保存
C#抓取当前桌面完整信息源码
鼠标+shift多选,鼠标+alt多个删除 3 读入链接文件对其自动另存 4 对文件按照内容源代码进行截取后自动入库 5 自动判断下一页链接来自动导入链接 6 在网页中利用正则表达式来进行特殊数据的抓取 7 ...
此系统分为前台页面展现和后台控制台数据采集。 三、菜单功能 1、股票查询:查询指定股票的持股基金数、基金持股数和基金持仓市值。查看持有该股票的所有基金信息,包括基金代码、基金简称、基金类型、基金规模...
各领域数据集,工具源码,...云计算与大数据:数据集、包括云计算平台、大数据分析、人工智能、机器学习等,云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。
每天股票数据抓取源码,通过sina公开接口,亲测有效,已经抓了半个月了,c# 的源码,包括数据字段说明
一、源码介绍 wpf prism sample 爬虫,淘宝MM,欢迎下载 二、注意事项 开发环境为Visual Studio 2017,无数据库,使用.net 4.5开发。
用c#提供方法给js, js便可实现采集数据的功能 先 show 下 js代码: function get_contents(){ try{ var url=$("#url").val(); // '{"a":"11","b":"22"}' 这个是传递过去的参数,回来的时候的 标识 window....
天猫产品图文详情页产品图片抓取保存,原理很简单,首先是根据地址获取页面内容,因为天猫的产品页面结构都是一样的,直接根据正则分析其中图片,然后保存即可。http://www.jinliniuan.com/archives/1244
HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽, 快速地进行生成,过滤,转换等操作。其功能最适合的领域,是爬虫和数据清洗。 Hawk的含义为...
C#版本的多线程数据采集,不错的版本,数据抓取的可以看看
这个爬虫用实验室十台电脑一起干活,可随时添加删除机器,具有良好的伸缩性,为了能够实现断点续爬和多台电脑之间的协作使用了Redis作队列, 为了保证不重复爬取使用Redis作hash表,所有爬取的任务都放到hash表中进行...
方便开发写了一个简单的测试工具,可以直接输入transit-id,也可不输入自动生成。会将下载出来的数据解密展示。